Extensible markup Language
Extensible markup Language
![]()
|
|
|
Extensible Markup Language, abbreviated XML is a Meta language. XML describes a class of data objects called XML documents and partially describes the behavior of computer programs which process them. XML is an application profile or restricted form of SGML, the Standard Generalized Markup Language. XML documents are made up of storage units called entities, which contain either parsed or unparsed data. Parsed data is made up of characters, some of which form character data, and some of which form markup. Markup encodes a description of the document's storage layout and logical structure. XML provides a mechanism to impose constraints on the storage layout and logical structure With XML you can · Define data structures · Make these structures platform independent · Process XML defined data automatically · Define your own tags XML Tags: Tags XML tags are created like HTML tags. There's a start tag and a closing tag. <TAG>content</TAG> The closing tag uses a slash after the opening bracket, just like in HTML.The text between the brackets is called an element. Syntax The following rules are used for using XML tags: _ Tags are case sensitive. The tag <TRAVEL> differs from the tags <Travel> and <travel> _ Starting tags always need a closing tag _ All tags must be nested properly _ Comments can be used like in HTML: <!-- Comments --> _ Between the starting tag and the end tag XML expects the content.<amount>135</amount> is a valid tag for an element amount that has the content 135 Empty tags Besides a starting tag and a closing tag, you can use an empty tag. An empty tag does. Not have a closing tag. The syntax differs from HTML: <TAG/> Elements and sub elements: Elements and children With XML tags you define the type of data. But often data is more complex. It can consist of several parts.To describe the element car you can define the tags <car>mercedes</car>. This model might look like this: <car> <brand>volvo</brand> <type>v40</type> <color>green</color> </car> Besides the element car three other elements are used: brand, type and color. Brand, type and color are sub-elements of the element car. In the XML-code the tags of the sub-elements are enclosed within the tags of the element car. Sub-elements are also called children. XML Attributes: Attributes Elements in XML can use attributes. The syntax is: <element attribute-name = "attribute-value">....</element> The value of an attribute needs to be quoted, even if it contains only numbers. An example
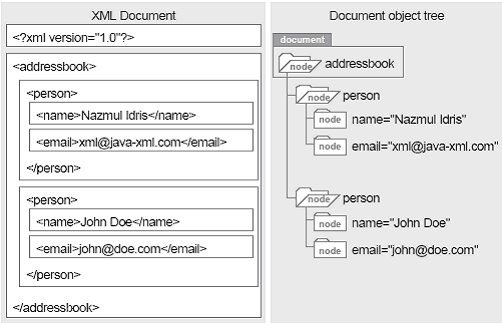
The same information can also be defined without using attributes: <car> <brand>volvo</brand> <color>green</color> </car> Why XML? The benefits of using XML are · XML is structured · XML documents are easily committed to a persistence layer · XML is platform independent, textual information · XML is an open standard · XML is language independent · DOM and SAX are open, language-independent set of interfaces · XML is web enabled · XML is totally extensible · XML supports shareable structure (using DTDs) · XML enables interoperability DOM (Document Object Model): A DOM XML parser is a Java program that converts your XML documents into some Java object model. Once you have parsed an XML document, it exists in the memory of you Java Virutal Machine as a bunch of objects. When you need to access or modify information stored in the XML document, you dont have to manipulate the XML document file directly, instead you must access and modify the information through these objects in memory. So the DOM XML parser creates a Java document object representaion of your XML document file. DOM gives you access to the information stored in your XML document as a hierarchical object model. DOM creates a tree of nodes (based on the structure and information in your XML document) and you can access your information by interacting with this tree of nodes. The textual information in your XML document gets turned into a bunch of tree nodes. DOM is similar to the Swing component models, like TableModel, ListModel and TreeModel. These models are simply interfaces which must be implemented by classes that contain the actual data.
DOM tree based object model for information in an XML document
If your XML documents contain document data (e.g., Framemaker documents stored in XML format), then DOM is a completely natural fit for your solution. If you are creating some sort of document information management system, then you will probably have to deal with a lot of document data. An example of this is the Datachannel RIO product, which can index and organize information that comes from all kinds of document sources (like Word and Excel files). In this case, DOM is well suited to allow programs access to information stored in these documents.
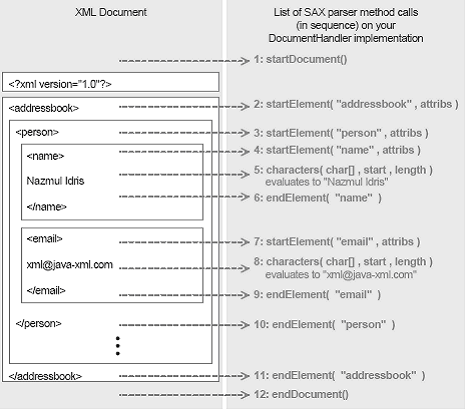
SAX (Simple API for XML): SAX stands for the Simple API for XML. Unlike DOM (Document Object Model) which creates a tree based representation for the information in your XML documents, SAX does not have a default object model. This means that when you create a SAX parser and read in a document (unlike DOM) you will not be given a nice default object model. A SAX parser is only required to read in your XML document and fire events based on the things it encounters in your XML document. Events are fired when the following things happen: · Open element tags are encountered in your document · Close element tags are encountered in your document · #PCDATA and CDATA sections are encountered in your document · Processing instructions, comments, entity declarations, are encountered in your document. The three steps to using SAX in your programs are: · Creating a custom object model · Creating a SAX parser · Creating a DocumentHandler (to turn your XML document into instances of your custom object model).
SAX DocumentHandler interface methods and their sequence
If the information stored in your XML documents is machine readable (and generated) data then SAX is the right API for giving your programs access to this information. Machine readable and generated data include things like:
· Queries that are formulated using some kind of text based query language (SQL, XQL, OQL) · Result sets that are generated based on queries (this might include data in relational database tables encoded into XML). |
|
|